MNIST识别手写数字
经过前几篇教程的学习,我们对于MNIST和TensorFlow已经有了很深入的了解了。这时候大家是不是有个疑问,我们光用这个网络模型来测试在MNIST数据集上识别的正确率有什么实际意义呢?在深度学习中,模型的任务一般分为分类和回归两类,训练出来的网络模型在实际中的应用大多是给他一个未知的输入,完成相应的分类或回归的任务。而我们就可以使用之前通过MNIST数据集训练的网络模型来完成对手写体数字的识别,你可别小瞧这个简单的任务,对人类来说是就是瞅一眼的事儿,对计算机来说可是要多动脑筋的呢!
接下来我们就来看看这次识别任务要识别的手写体是啥样的:
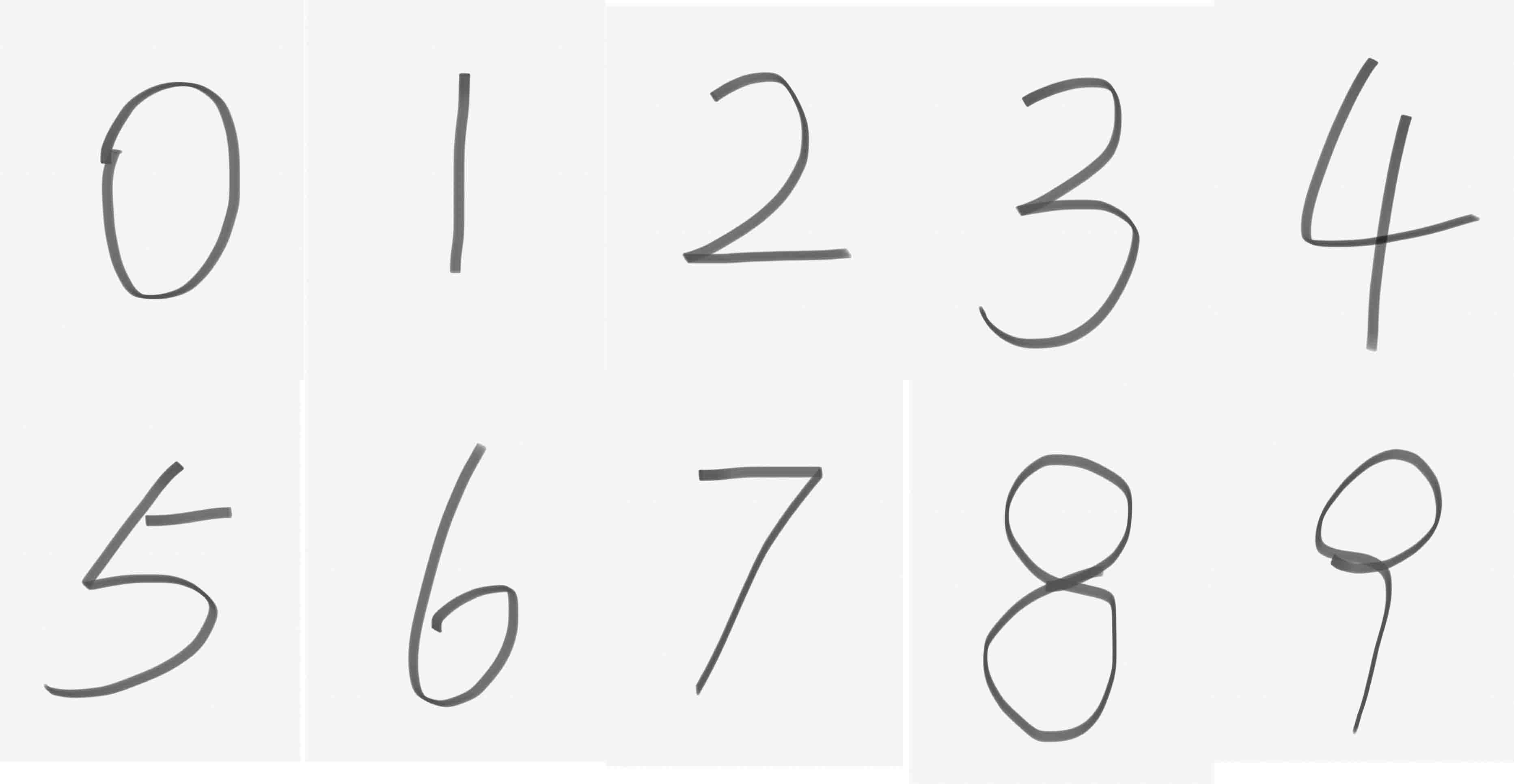
虽然和MNIST数据集的手写体数字有一定差别(感兴趣的可以看看我之前的第五篇里有,是属于比较飘逸的字体),但是这么工整的字体当然是难不倒我们的网络啦~
PIL的使用
现在我们有了一个使用MNIST数据集训练好的网络,有了10张待识别的手写体数字图片,那么问题来了,我们怎么像PPAP一样把这个网络用于这些图片的识别?这时候我们的PIL就可以出场啦!
PIL:Python Imaging Library,已经是Python平台事实上的最基础的图像处理标准库了(当然量级更大些的OpenCV也是非常实用的,不过这次的任务暂时还用不到~)。该库支持多种文件格式,提供强大的图像处理功能,但API却非常简单易用。
Ubuntu中PIL的安装
Ubuntu中PIL的安装是非常简单的,通过apt:
$ sudo apt-get build-dep python-imaging
$ sudo apt-get install libjpeg8 libjpeg62-dev libfreetype6 libfreetype6-dev
$ sudo pip install Pillow
通过查看版本查看PIL是否安装成功:
$ python
>>> import PIL
>>> PIL.VERSION
'1.1.7'
如果没有安装成功的,根据提示先把缺失的包装上。如果是以下两个问题可以对应解决。 Q&A
- Ubuntu使用apt-get时提示>”E: You must put some ‘source’ URIs in your sources.list”。
$ sudo sed -i -- 's/#deb-src/deb-src/g' /etc/apt/sources.list && sudo sed -i -- 's/# deb-src/deb-src/g' /etc/apt/sources.list $ sudo apt-get update - 执行apt-get update时提示W: Failed to fetch http://cn.archive.ubuntu.com/ubuntu/dists/natty/universe/source/Sources 404 Not Found
$ cd /etc/apt/sources.list.d $ sudo mv filename filename.bak # 将提示对应的包改名备份即可(也就是删除该包)
使用Image类
PIL中最重要的类是Image类,该类在Image模块中定义。
从文件加载图像:
import Image
im = Image.open("lena.png")
如果成功,这个函数返回一个Image对象,可以使用该对象的属性来探索读入文件的内容。
操作图像
来看看最常见的图像缩放操作,只需三四行代码:
import Image
# 打开一个jpg图像文件,注意路径要改成对应的,绝对相对都可以:
img = Image.open('./test.jpg')
# 获得图像尺寸:
w, h = img.size
# 缩放到50%:
img.thumbnail((w//2, h//2))
# 把缩放后的图像用jpeg格式保存:
img.save('./thumbnail.jpg', 'jpeg')
其他功能如切片、旋转、滤镜、输出文字、调色板等一应俱全。比如,模糊效果也只需几行代码:
import Image, ImageFilter
img = Image.open('./lena.jpg')
img2 = img.filter(ImageFilter.BLUR)
img2.save('./blur.jpg', 'jpeg')
PIL的ImageDraw提供了一系列绘图方法,让我们可以直接绘图。比如要生成字母验证码图片:
import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母:
def rndChar():
return chr(random.randint(65, 90))
# 随机颜色1:
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
# 240 x 60:
width = 60 * 4
height = 60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象:
font = ImageFont.truetype('Arial.ttf', 36)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save('code.jpg', 'jpeg');
我们用随机颜色填充背景,再画上文字,最后对图像进行模糊,得到验证码图片如下:

如果运行的时候报错:
IOError: cannot open resource
这是因为PIL无法定位到字体文件的位置,可以根据操作系统提供绝对路径,比如:
/Library/Fonts/Arial.ttf'
要详细了解PIL的强大功能,还请参考PIL官方文档,有比较详尽的介绍。
PIL对手写体数字的预处理
在了解了PIL的一些基本使用方法之后,我们就可以开始对我们的9张手写体数字的图片进行预处理啦!由于我们的网络训练的时候是使用的MNIST数据集,因此我们需要把我们的手写体数字的图片也处理成一样的输入才可以。
看过之前教程的朋友们应该已经知道了,MNIST网络模型输入图片的SIZE是 28 x 28 这个大小的,因此我们也需要把我们的原图(749 x 936)resize成这个大小,但是这个过程是会有一些问题的,如果直接使用resize函数会带丢失掉原图的很多信息。由于本次任务比较简单,我们可以直接用resize函数,在这之前还可以使用convert('L')先把原图转为8位灰度图微微降低直接resize所带来的影响,同时转为灰度图也是为了处理简单(否则直接使用RGB三通道计算较复杂且没有必要)。
除此之外,我们还需要额外关注一下MNIST的输入图片到底是黑底白字还是白底黑字(影响到是否要取反)。可以看到MNIST的输入图片的数字部分(前景)是白色的,而背景部分是黑色的,即黑底白字;但是我们的手写体数字图片是白底黑字的,因此需要我们对整个手写体数字的图片取个反(取反在转为数字的图像中非常简单,比如0~255的灰度图,用255去减每个像素的亮度值即可;若是已经二值化的图像,可用1去减)。
最后,我们光有灰度图是不够的,我们的输入最终是需要一个二值化的图像,而每个像素的8位灰度值是一个0~255的数,这时候就需要除一个阈值进行二值化(归一化到0~1之间)。这个阈值在复杂任务中可以选用OTSU算法进行自适应阈值选取,但是在我们这个简单的任务中,通过实验获得较好的经验值是在200。
经过上述分析,我们就可以写出对手写体数字的图片做读取输入并且预处理的程序了:
def img_read():
number = str(input("please input one number:"))
img = Image.open("./handwriting_number/" + number).convert('L').resize((28, 28))
imgbin = 1 - (np.array(img) ) / 200 #二值化图像并取反,除数是阈值
print imgbin
imgline = imgbin.reshape(1, 784)
#print imgline
return imgline
img_read()函数先是让用户输入一个图片的编号(对应上边的那10张手写体数字的图片),接着使用PIL库打开对应待识别图片,转为灰度图(单通道),resize成 28 x 28 的大小,使用到了numpy库对图像进行阈值二值化、取反的操作,并reshape成 1 x 784 维度的一个向量返回,之后只需把返回值作为输入喂入我们之前已经训练好的前向传播网络即可。
使用PIL与MNIST识别模型识别手写数字
在系列教程的第五章,我们介绍了如何保存和加载TensorFlow模型,这时候就要派上用场啦!如果已经忘记了如何加载保存好的TensorFlow模型可以翻回去看看~在这里我们要使用之前已经通过CKPT格式保存好的训练MNIST的网络,把模型加载进来,并且通过PIL把待识别的手写数字输入到模型中,跑一遍前向传播的过程即可得出最终的分类结果。